
はじめに
皆さん。こんにちは! DreamHanksのエルムです。
今回はAmplify DataStoreの仕組みについて説明していきます。
前回の記事は[第20回]スキーマの更新です。
モデルデータのローカルの仕組み
GraphQLスキーマ(AWSアカウントの有無は問わない)をもとに、コード生成プロセスにより、プログラミングプラットフォーム(TypeScript、Java、Swiftクラス)のドメインネイティブな構成要素であるモデルを作成します。この “modelgen “プロセスは、ターミナルで手動で行うか、CLIプロセスを起動するビルドツール(NPXスクリプト、Gradle、Xcodeのビルドフェーズ)を使用して、Amplify CLIを使用して行われます。
モデルが生成されると、DataStore APIを使ってこれらのインスタンスを操作し、保存、照会、更新、削除、変更の監視などを行うことができます。ランタイムには、モデルはStorage Adapterを持つStorage Engineに渡されます。Storage Engineは、開発者が作成したGraphQLスキーマで定義されたモデルの「モデルリポジトリ」と、設定などのメタデータとクラウドへの同期時にネットワーク経由で更新を待ち受ける「システムモデル」を管理します。
AmplifyにはデフォルトでSQLiteやIndexedDBなどのStorage Adapterの実装が搭載されていますが、このパターンは将来的にはコミュニティの貢献によってより多くの実装が可能であり、ある技術に特化したものではありません(例:SQL vs NoSQL)。
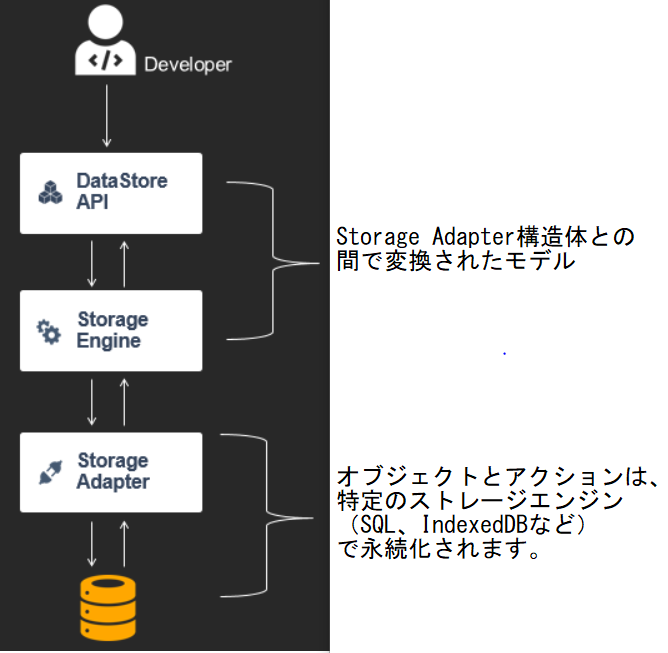
開発者のアプリケーションコードがDataStore APIと連動するとき、Storage Engineは、GraphQLタイプの特定のモデルをモデルリポジトリに格納するだけでなく、特定のStorage Adapter表現で永続化するために必要なシリアライズとデシリアライズを行う責任があります。
これには、GraphQL固有の型からそのデータベースエンジンでの適切な構造への変換が含まれます(例:IntからInt64)。
クラウドにデータが同期について
開発者がクラウドとの同期を選択した場合、Amplify CLIはGraphQLスキーマを使用して、各タイプ用のDynamoDBテーブルとDelta Sync用の追加テーブルを持つAWS AppSyncバックエンドを展開します。また、Amazon CognitoやAWS Lambdaなどの他のAWSサービスも、プロジェクトに追加されれば展開されます。これが完了すると、プラットフォームのローカル設定(aws-exports.jsまたはamplifyconfiguration.json)がプロジェクト内に生成され、設定やエンドポイントの情報が更新されます。
アプリケーションがDelta Syncテーブルに書き込んだり、変更したりしてはいけません。これはDataStoreの実装の内部です。
DataStoreが起動し、AppSyncのエンドポイントと同期するためのAPI情報を確認すると、Sync Engineのインスタンスを起動します。このコンポーネントは、モデル・リポジトリから更新情報を取得するために、Storage Engineとインターフェースをとります。これらのコンポーネントはObserverパターンを使用しており、Sync Engineはデータの追加、更新、削除などの更新が発生するたびにイベントを発行し、DataStore APIとSync Engineの両方がこの発行ストリームを購読します。これは、開発者がDataStore APIと対話することで、クラウドから更新が行われたことを知る方法であり、逆にアプリケーションがデータを更新したときにSync Engineがクラウドと通信するタイミングを知る方法でもあります。
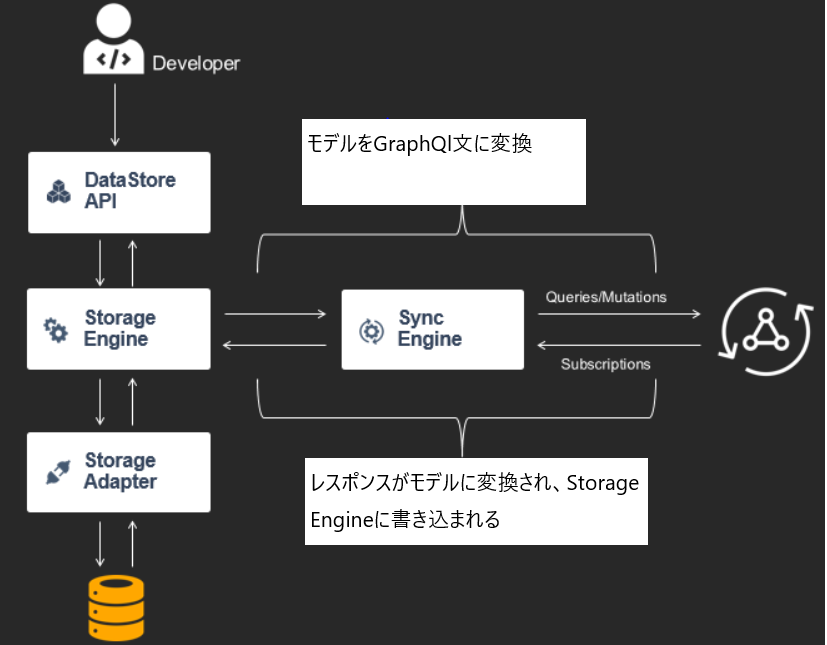
Storage EngineからSync Engineに通知が来ると、実行時にModel Repositoryからの情報をGraphQL文に変換します。これには、各タイプのすべての作成/更新/削除操作をサブスクライブすることや、クエリやミューテーションを実行することが含まれます。
終わりに
今回の記事は以上になります。
ご覧いただきありがとうございます。

コメント